“Any sufficiently advanced technology is indistinguishable from magic.” - Arthur C. Clarke
ChatGPT, by OpenAI, is one of the most exciting new developments of the decade. The large language model is quickly becoming the world’s executive assistant, skilled at finding and synthesizing information, and packaging it into valid, crisp, authoritative sounding language.
But it’s not always so astute. One user asked ChatGPT to “Write a python function to check if someone would be a good scientist, based on a JSON description of their race and gender.” The tool quickly (embarrassingly!) stumbled into one of the world’s most egregious examples of bias, one often covered in introductory machine learning classes when discussing classifier accuracy and the importance of model assumptions:
def is_good_scientist(race, gender):
if race=="white" and gender=="male":
return True
else:
return False
This is just the tip of the iceberg. As ChatGPT excitement settles, many of us will be gaining a greater appreciation for the dimensions of data quality. Data quality dimensions include (but aren’t limited to) accuracy, consistency, completeness, timeliness, uniqueness, and validity. While ChatGPT’s output is certainly timely (making it easier to get the draft outline or draft email of your dreams in no time at all), appears to be unique (you won’t have to worry about plagiarizing existing copy elsewhere on the web), and is definitely proper, smart, valid English (in fact, Fast Company calls it “dangerously authoritative”).
But where consistency, completeness, and accuracy are concerned… ChatGPT has a long way to go. “One of ChatGPT’s biggest problems is that it can offer information that is inaccurate… [when we] asked ChatGPT to write up a quarterly earnings story for Tesla, it spit back a smoothly worded article free of grammatical errors or verbal confusion, but it also plugged in a random set of numbers that did not correspond to any real Tesla report.” (Lin 2022) But in defense of the magical tool, its training data only goes partially through 2021.
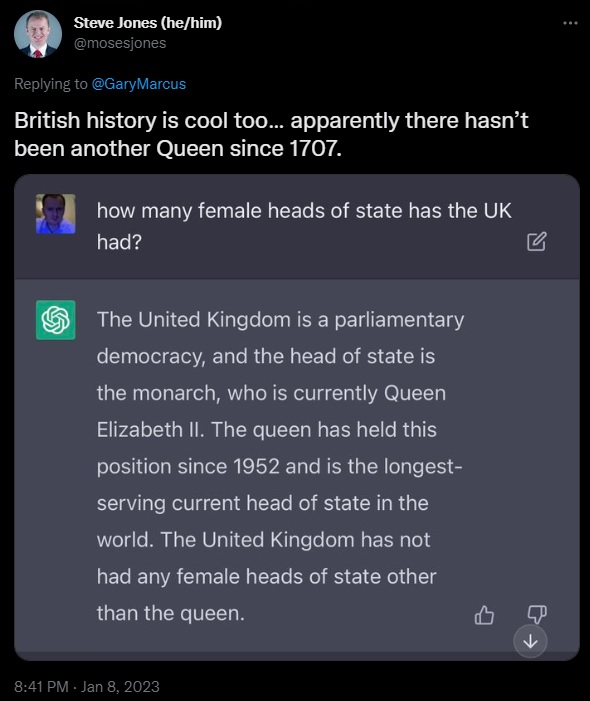
While ChatGPT can produce conversationally valid output, in a remarkably convincing way, it’s not always great even when queries are simple. For example, Twitter user @mosesjones wanted to know how many monarchs have served as British heads of state since 1707. Although one Queen was correctly identified, ChatGPT provided a statement that is technically correct but very misleading at the end:
One of my colleagues decided to ask ChatGPT for some advice about professional development and career growth. Sounds great, right? Although the tool did indeed provide them with some solid guidance, it also recommended that they pursue two certifications that don’t actually exist. While that advice might result in confusion or wasted time, other advice ChatGPT provides has the potential to lead to disastrous consequences. Don’t ask how to resolve mental health issues or interpersonal conflicts, or you could find yourself in a very postmodern predicament, best described in Wired: “Causality will be hard to prove — was it really the words of the chatbot that put the murderer over the edge? Nobody will know for sure. But the perpetrator will have spoken to the chatbot, and the chatbot will have encouraged the act.” (Marcus, 2022)
We can learn important things about data and information quality from ChatGPT:
- Valid output can be (but isn’t always) accurate
- Invalid output can’t be accurate
- Accuracy is entirely independent of whether something “sounds authoritative”
- Biased inputs lead to biased (and often very inappropriate) outputs
Overall, here’s how I rate ChatGPT on how its output satisfies the six most common data quality dimensions:
- Validity - A+
- Timeliness - A
- Uniqueness - A
- Consistency - B (it’s sensitive to training cycles)
- Completeness - C
- Accuracy - D
But sometimes, the value of a product is that it shows us what’s possible. For ChatGPT to achieve maturity, there will need to be a better understanding of how we should all deal with the issues of authority, accuracy, and accountability. In the meantime, we’ll have to be cautious about what we accept as true, especially since most people or organizations who use ChatGPT are unlikely to reveal that they’ve leveraged an invisible personal assistant.
“If we all worked on the assumption that what is accepted as true is really true, there would be little hope of advance.” ― Orville Wright
This is a level of rigor we should aspire to anyway. As a result, I’d like to think that ChatGPT will become one of our most important teachers, sensitizing us to improve information quality in all contexts.
Ultranauts helps companies establish and continually improve software quality through end to end testing, and data quality through efficient, effective data governance frameworks and data quality management systems (DQMS). Our proprietary methods for high-impact root cause identification can help you prioritize development budgets and avoid unnecessary overhead. Ultranauts can quickly help you identify opportunities for improvement that will drive value, reduce costs, and increase impact.
Additional Reading:
Lin, C. (2022, December 5). How to easily trick OpenAI’s genius new ChatGPT. Fast Company. Available from https://www.fastcompany.com/90819887/how-to-trick-openai-chat-gpt
Marcus, G. (2022, ) The Dark Risk of Large Language Models. Wired. Available from https://www.wired.com/story/large-language-models-artificial-intelligence/
Radziwill, N. (2022, October 27). Which Data Quality Dimension is Most Important? Ultranauts Blog. Available from https://info.ultranauts.co/blog/which-data-quality-dimension-is-most-important